To tell you the truth, life has been a whirlwind of activity in recent weeks. Relentless pace of work, deadlines, bureaucracies, all of them combined left me feeling much more tired than usual, mentally and physically. But the big batch of calculations are finally finished; I just need now to finish the reports (no factor–gonna finish it in a single sitting on Monday), and this weekend I finally got some peace and spare time of my own.
While browsing internet, I found some things that I thought interesting. Apparently, nowadays there are several twitter bots such as @LmaoGPT and @ReplyGPT that leverage the LLM (Large Language Model) to automatically create replies to tweets that mention them. You should check them out, by the way, they’re really interesting. Anyway, from them, I was inspired, and I thought to myself: why couldn’t I make something like that myself? Something that can leverage OpenAI’s GPT API?
So I started out like that, starting the python project, installing openai’s API, getting the API Key (I’ve been using ChatGPT for a while, and I’ve had the API for a while too for some work-related projects, but this is the first time I created one for my own project), testing them with some prompts, and then I ask myself: what should I make?
I know that question should’ve been asked right at the very beginning (笑) before I even started the project. I browsed around a little bit more, opened up my email and caught up with some newsletter, found that some of them a bit too long to read and I better save it for later time, and that’s when it hit me: a TL;DR assistant! I could use ChatGPT for TL;DR-ing long articles, to make them shorter and easier to read. What’s more, with OpenAI API’s request format, I could even tell the GPT to generate summaries with certain characteristics: maximum or minimum length, tone of the text, and many more.
Challenges
Of course, not everything is fine and dandy. Very quickly, I found myself facing several problems.
The article retrieval itself is not a problem. A little beautifulsoup4 magic and it’s more or less done: make the request to the URL given by the user, extract its text, and save them as a string variable. Not difficult.
Then I found myself facing the first challenge: the infamous token limit of OpenAI’s API. As explained here, my problem can be summed up quite simply by the following paragraph:
Depending on the model used, requests can use up to 4097 tokens shared between prompt and completion. If your prompt is 4000 tokens, your completion can be 97 tokens at most.
This was actually quite a bigger problem than I expeted. Especially for something like an article summarizer, where we expect to send a prompt consisting of thousands of words, or tens of thousands of characters. Luckily for me, the hint for the solution to this problem is also written in the paragraph right after it:
…there are often creative ways to solve problems within the limit, e.g. condensing your prompt, breaking the text into smaller pieces, etc.
So that’s what I did. With a pair of simple functions, I first divide the text from the URL into several chunks, and then I make the summary for each chunks before sending the summaries of all the chunks to the final request to the API that’ll make the final summary. This, of course, requires several request to the OpenAI API, but it solves the problem at least for now.
(Hopefully, though, one day we wouldn’t have to do this again and we can send longer and longer text to the API endpoint in one go.)
The next challenge is about performances. As I said before, making summaries chunks by chunks will hinder the performance of the summarization process. We don’t want them to block each other, to wait each other to finish!
Luckily, we have async-await in Python. By changing the whole preprocessing and processing functions into asynchronous, the chunks can be processed without blocking one another.
Finally, there’s the problem of repeat summarization. Sending request to OpenAI’s API every single time a URL is submitted, even though the URL is the same, will quickly burn through the quota that I have. Thus, a caching system is important. I don’t want the caching to cause the same results every single time for the same URL though, so I was thinking of implementing it only for the summarization of chunks, not for the final one.
Then came the question of how to implement it. I was thinking of using Streamlit’s native st.cache_data functionality, but I found out quickly that it’s not really compatible with async-await functionality in Python. Not only that, I also want the cache to expire after certain time (one hour sounds enough for me). Of course, there could be some tricks to make it work, but I want something simpler–something that can work out of the box without me having to reinvent the wheel.
Luckily we have TTLCache from cachetools. It provides a quite high-level way to cache functions’ results and make it expire after certain interval of time has passed. So I implement it on the preprocessing part, and all is good!
Results
Just like my old twitter scraper project (it’s still not fixed following Twitter’s API update; I swear once I get enough spare time–probably two or three days–I’ll fix it), I decided to deploy the app on Streamlit Cloud. It works quite fast (even with me still using the Free Plan) and I’m quite happy with how it turned out. Some screenshots below:
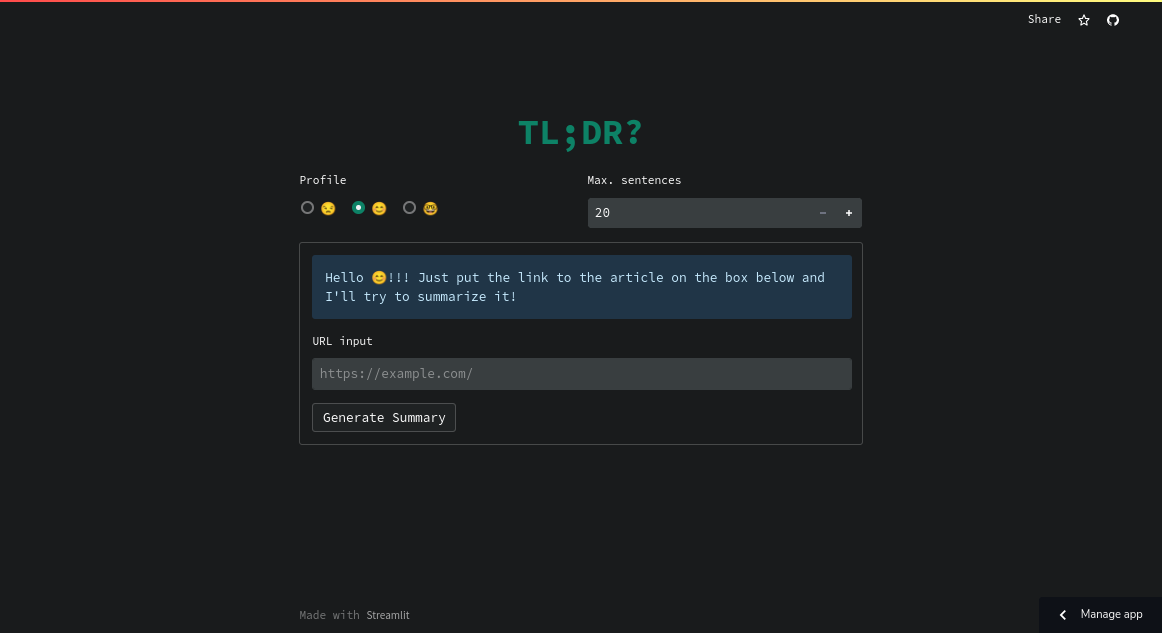 |
|---|
| Landing page |
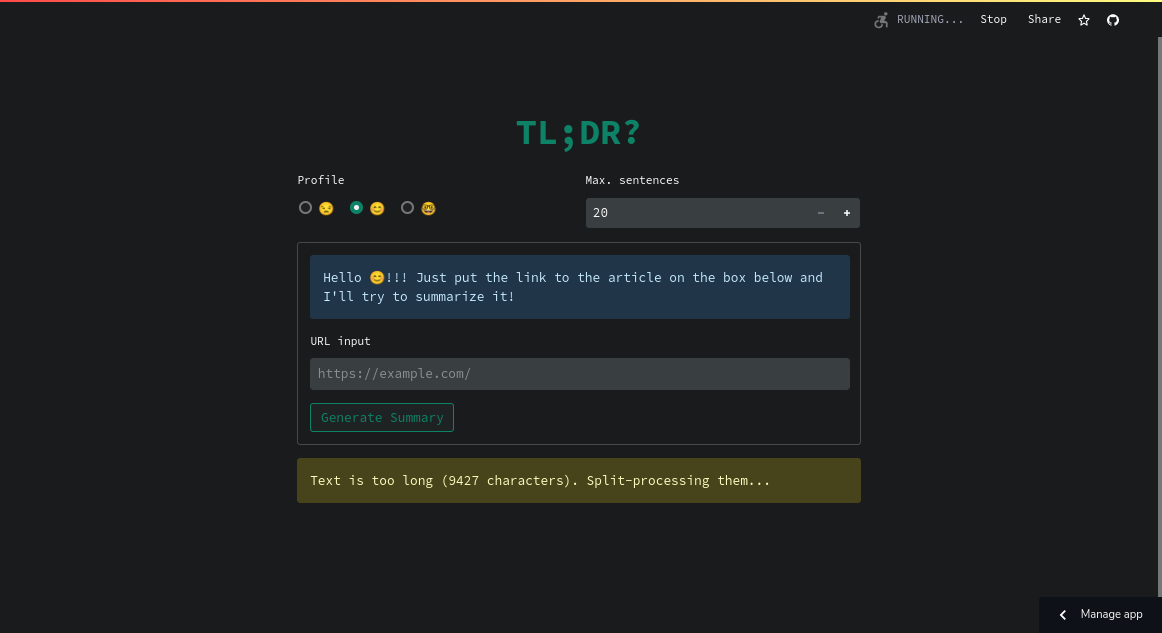 |
|---|
| Summarization in-progress |
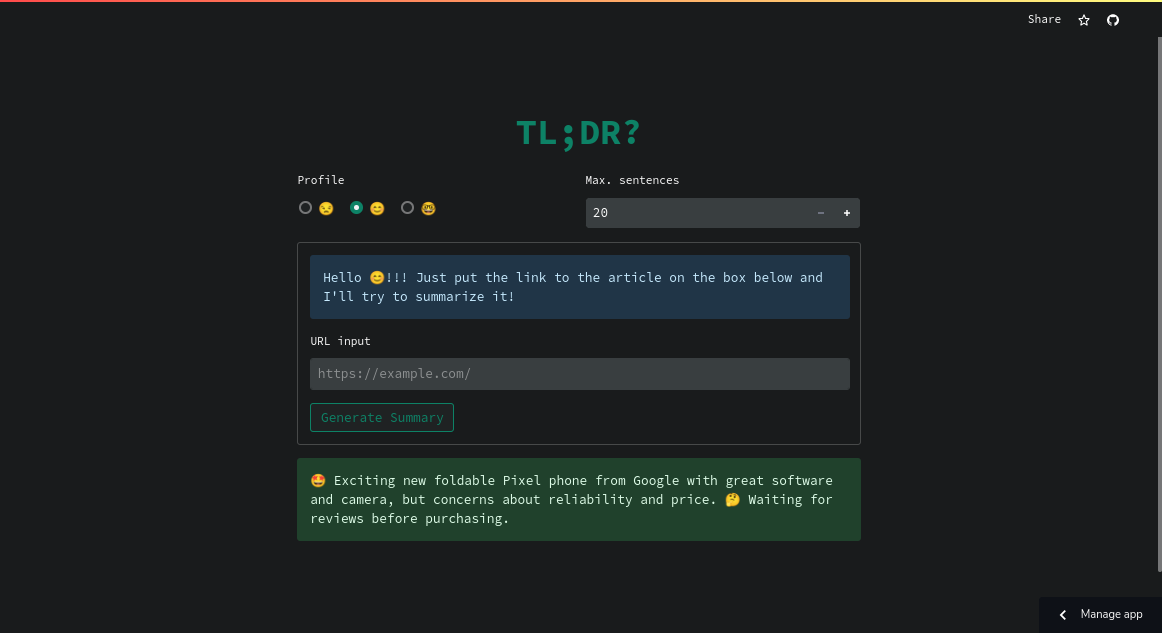 |
|---|
| In no way or form do I profit from this post or has any commercial relations/interests/endorsements with Google at all |
Currently, it’s up and running and available on tldrgpt-web.streamlit.app. If you want to try it out, please go ahead! If you want to clone it and run it locally with your own OpenAI’s API Key, you’re also welcome! Found some bugs or problems? You’re welcome to open some Issues on the repo or comment here. I’ll always try to get back to you as soon as I can!