Weekend, finally! Past weeks have been so intense both at work and home. It feels good being able to finally breathe a little bit. I hope everybody who’s reading this are having great time!
Speaking of great time, honestly, there used to be such time period in my life where weekends mean full days on the road, traveling, visiting quiet picturesque villages in Southern France with my wife. Or perhaps go to a bookstore to find some new Murakami books. Or maybe visit that café that looks so cozy, enjoying matcha or a bit of Boba tea.
Well, those days are gone. Lately weekends are filled more with staying at home, resting ourselves after full week of work, watching TV, and maybe reading a little bit. Basically cozying up. Some friends told me it’s called “getting old”, and at this point, maybe I should be agreeing with him.
New Hobby and Tweet Cloud Maker
On the other hand, I also picked up a new hobby since couple months ago. That is learning game development. It’s still a bit too early for me to show anything, I’ve been doing basically nothing except following a lot of tutorials on YouTube to get hands-on learning (note: if you’re learning Pygame and looking for some excellent tutorials, I would recommend this channel called Clear Code wholeheartedly. Hands down the best Pygame tutorials I’ve ever seen. Practically teaching me about game dev workflow from zero). Nevertheless, I really aim to create my own game one day–maybe I should blog about it more later.
Anyway, this blog shouldn’t be about my painful but so far satisfying process of learning game development. Not really. What happened was that about one or two weeks ago, while I was tidying up my github repo a little bit (so many abandoned weekend projects, gosh), I suddenly found my old Tweet Cloud Maker repo again. It was archived, and I remember that it was archived because, after some changes in Twitter API (I believe it was some time early this year), the snscrape module–the primary module that I used to scrape tweets from Twitter–stopped working for me.
I remember myself not having too much time back then, and decided to take it down, promising myself to fix it one day.
Well I unarchived the repo and started working on it again. Immediately, I still found myself having the primary module not working for me. I opened up their repo, browsing for their Issues and started reading, and basically got stopped at the following phrase on their README:
It is also possible to use snscrape as a library in Python, but this is currently undocumented.
That was kind of unfortunate. I was thinking of probably being a contributor to the repo, study it and write some documentations while trying to find out the issue for me, when I realized that it would take a bit more time and that it’d probably be faster for me to fix my old twitter scraping module and use it for this app.
Enter the pytterrator
Sometime around early last year, I started getting more conscious about privacy. I tried to make some efforts to stop using many apps that soak my data consistently. I stopped using most of my social media and finally deleting it one by one (privacy’s not the only reason, but it plays a big role in my decision; I’ll probably write a blog about it later). I don’t really like the idea of companies I don’t know using my data for profit without my full informed consent.
I started looking for alternatives for using many of web services I’ve been using for a long time: Invidious for YouTube, SearxNG to replace Google, etc. One of the social media that I used consistently for searching up news around the world quickly is Twitter, and I stumbled upon Nitter, an alternative Twitter frontend that works with more or less the same principles as Invidious and SearxNG: get the data from the official site using API, strip away all the trackers, and display them in a cleaner, faster interface.
I like it. It’s lightweight, I don’t have to install any applications to find out what Elon Musk is tweeting for example. I liked it a lot that I decided to start a weekend project back then called pytterrator that, I imagine, would become a simple Python module allowing us to get tweets using Twitter’s API and some scraping (if necessary), one that I’d be able to use as a foundation for making a full webapp just like Nitter.
What Happened?
Nothing. Long story short lots of things fell upon my lap in 2022 at work. I somehow got promoted. I got new responsibilities. The project gathered dust for months, and in the few moments I got to return to it, I couldn’t manage to do anything significant. Couple that with the changes in Twitter’s API, I thought to myself that I wouldn’t be able to fix and develop it further (or even taking care of my other side-projects) without having to sacrifice my career and sanity.
That kinda changed now. With the company expanding and developing, and more and more automated systems are put in place, I found my works to be much more streammlined and easy to manage lately. It feels good knowing that the company is slowly maturing, no longer a tiny startup comprising of five engineers working together in a single office. Everything started to fall into a more disciplined, consistent and well-structured routines, and I found myself having more time for my own projects (hence starting the game devs hobby lol).
To cut the story short: I opened up again the pytterrator repo and managed to make it work. It’s still so raw, no documentations yet put in place (I’ll definitely prepare it soon, promise), but it works to scrape tweets from public account. It uses Twitter v1.1 API, it puts some limiters to itself, it can regenerate guest token if needed. So far, it just works.
(If you somehow trying it out and found some bugs on it please raise them as Issues or if you want you can help contribute directly! Would be really appreciated!)
Back to Tweet Cloud Maker
So that was four days ago. Then I came back to the more pressing problematic app of mine that is my Tweet Cloud Maker app. I decided to switch fully from the snscrape module to pytterrator.
The process wasn’t difficult at all. The scraper functions were simply removed and replaced by the methods defined in the pytterrator’s Client class. That alone managed to make the app up and running. It can scrape tweets up to certain number limit that we request (though I still put a limit of 1000 tweets–this could potentially change in the future after I experiment and develop more on the module to handle the rate limit). The tweets are then digested, words containing special characters were removed.
Then, as a bigger change, I simply remove the feature to scrape tweets between certain dates. The reason is simple: for now I haven’t implement the method to do this yet on pytterrator properly. Once I manage to do that on the module, I’ll simply update the module used in Tweet Cloud Maker and implement this new feature!
Results
Some screenshots of the app running:
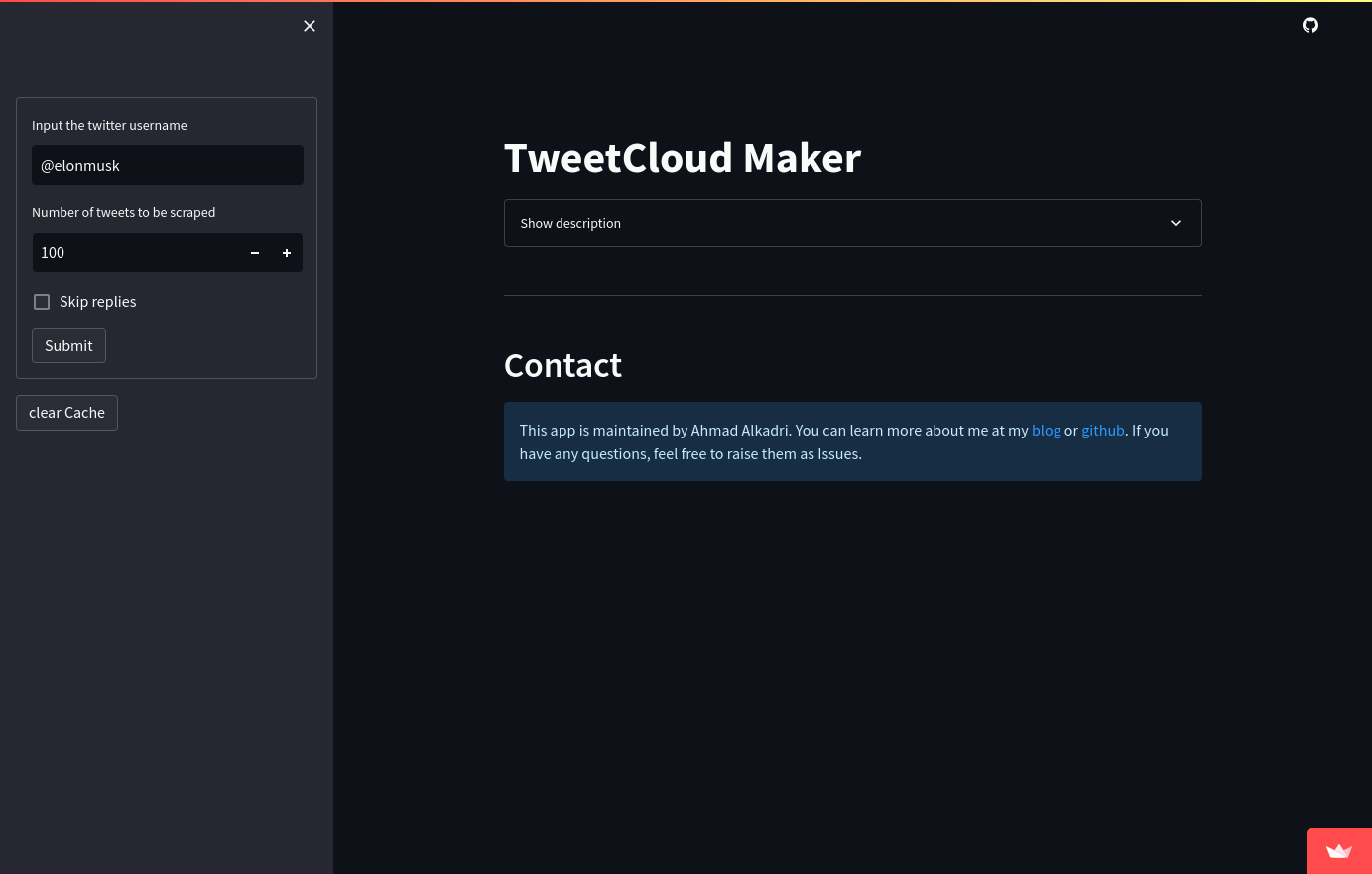 |
|---|
| Landing page |
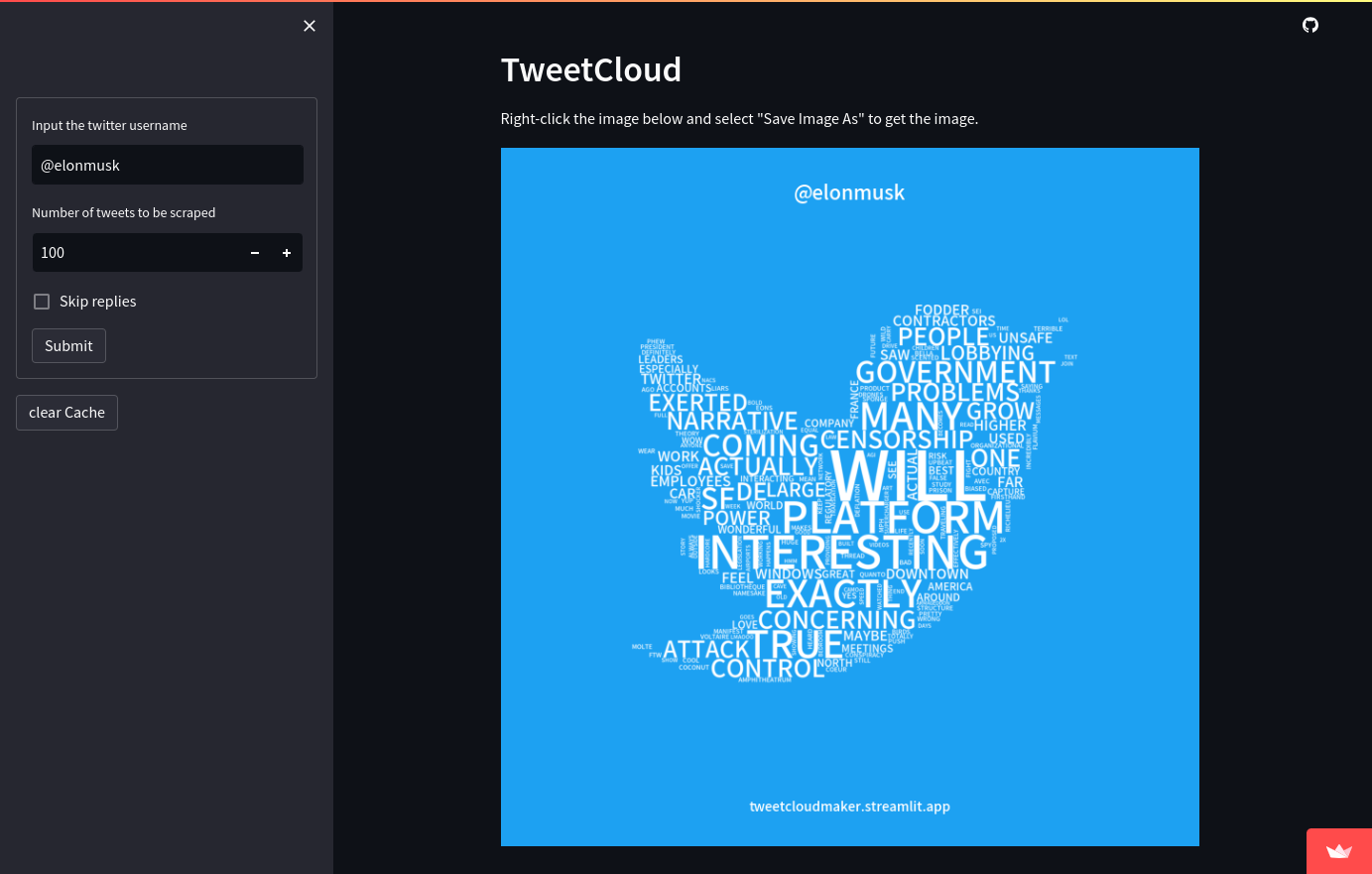 |
|---|
| Scraping Elon Musk’s tweets |
There are still some works that I’d like to do though. I’d like for it to be able to recognize Chinese, Japanese, and Korean character for example. I’ve initiated this work on the app but it’s far from done. Unlike alphabetic sentences, words in Japanese or Chinese are seldom divided by spaces. Korean sentences do this but some parts still poorly recognized by the app. Stopwords or special characters are also need to be handled differently. This is definitely one of the stuffs that I’ll work on in the future, together with the date/calendar-based scraping.
Currently, it’s up and running and available on its old address at Streamlit Cloud: tweetcloudmaker.streamlit.app. If you want to try it out, please go ahead! If you want to clone it and run it locally on your machine, you’re also welcome! Found some bugs or problems? You’re welcome to open some Issues on the repo or comment here. I’ll try to get back to you as soon as I can!
Once again wishing everyone a nice weekend!